
You know you are doing something wrong in your query when the timer at the bottom of pgAdmin runs out of room... and is still going
#postgresql #plpgsql
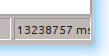
You know you are doing something wrong in your query when the timer at the bottom of pgAdmin runs out of room... and is still going #postgresql #plpgsql
Basically it was 1800 rows (of an 12M row dataset), joined against itself 6 times + 4 of those joins were "select max". This is a summary:
select ...
from daily t
inner join daily y on y.id = t.id and
y.day =(select max(day) from daily where day < h.day)
inner join daily h on h.id = t.id and
h.day between t.day-100 and t.day-1
inner join daily hp on h.id = t.id and
hp.day = (select max(day) from daily where day < h.day)
inner join daily f on f.id = t.id and
f.day between t.day+1 and t.day+100
inner join daily hp on h.id = t.id and
hp.day = (select max(day) from daily where day < h.day)
where price > 5 and close > 0 and...
group by ...
having ...
Not quite right.
I have it down to 1162ms: now I can safely run it against the full 12M rows.
There were a few problems (one fixed):
1. The compounding of the query (I ran this agains the 12M rows and it took ~1 second, so the joins are no longer a significant part of the cost)
2. The select has a lot of aggregate queries, some of which are custom, most of which are unnecessary. I'm suspicious of this, especially when you watch the CPU usage vs Memory Usage
3. This is running on my laptop with a fresh install of Postgres: I haven't tuned any of the server resource allocations (low memory usage etc.). Though it appears this query is bottle-necking at the CPU (all those aggregrate functions.
At this point I get to say "fast enough", while I explore (what I think is) a deadlocking issue I created for myself </ rolleyes>
I don't even have names for those kinds of numbers. (6.19*10^16)
In the past, it has been my policy to not backup calculated values... since they can be recalculated if lost. My experience restoring this system has shown that, under some conditions, waiting for the recalc may not be feasible.
I certainly wasn't prepared to wait 1300 years (4.5 hours/period * ~2500 periods) for the dataset to be rebuilt. Testing of backups, as done in production systems, would have highlighted the problem.